Modern text-to-image diffusion models encode rich visual priors but expose them only through one-way,
text-conditioned generation. Existing unified vision–language models derived from them recover
bidirectional capability through large-scale joint pretraining or substantial retraining of the text pathway,
discarding the strong image prior the text-to-image backbone already encodes.
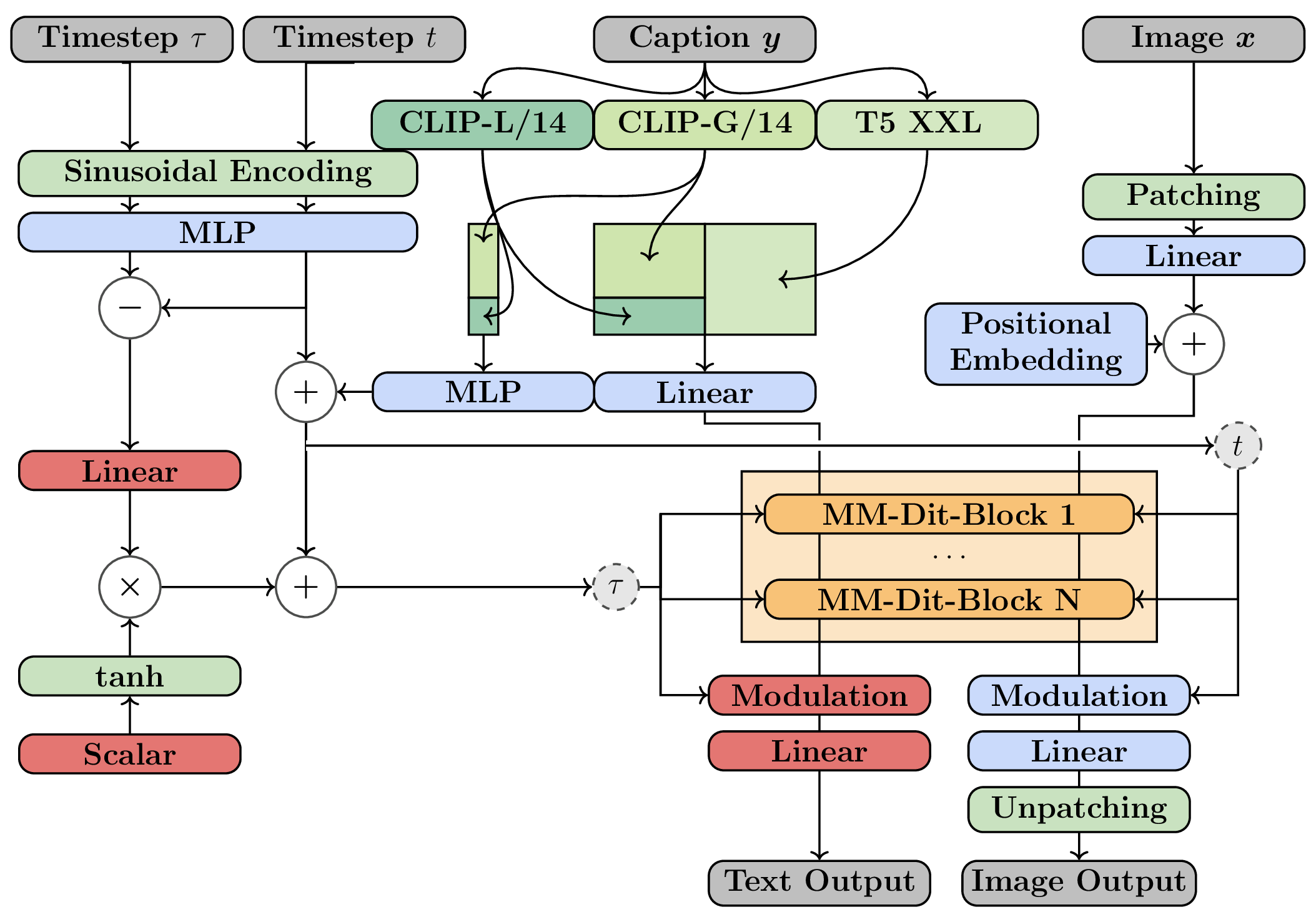
We introduce FullFlow, a parameter-efficient recipe that upgrades a pretrained rectified-flow
text-to-image model into a bidirectional vision–language generator by training only LoRA adapters and
lightweight text heads. FullFlow keeps images in their native continuous flow and adds a discrete
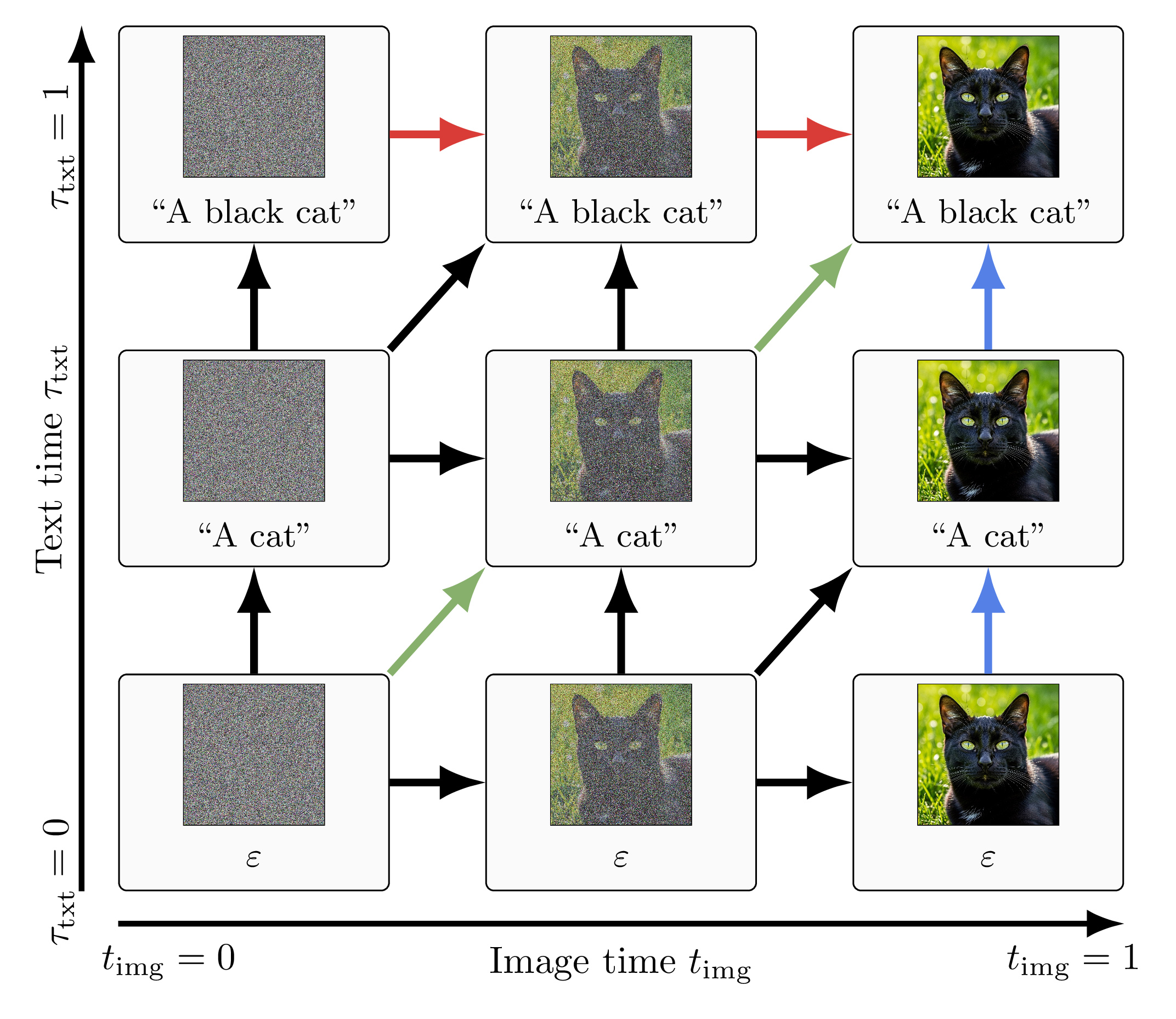
insertion process for text. Separate image and text timesteps turn inference into trajectory selection in a
two-dimensional generative space, enabling text→image, image→text, joint sampling, and partial-text
prediction with a single backbone.
On Stable Diffusion 3 under an identical trainable-parameter count and matched LoRA rank, FullFlow
improves text→image FID from 62.7 → 31.6 and image→text CIDEr from 2.0 → 99.4 over a
LoRA equivalent of the previous SOTA (Dual Diffusion) at matched wall-clock time, while reducing peak
VRAM from ~84 GB to ~38 GB and raising throughput by ~8× on two RTX A5000 GPUs in under 24h
— training only ~5% of the backbone. The same recipe transfers to FLUX.1-dev and supports
downstream VQA through partial-text generation.
C1 — Recipe
Convert a pretrained text-to-image rectified-flow model into a bidirectional vision–language generator by training
only LoRA adapters and lightweight text heads, while preserving the pretrained image prior.
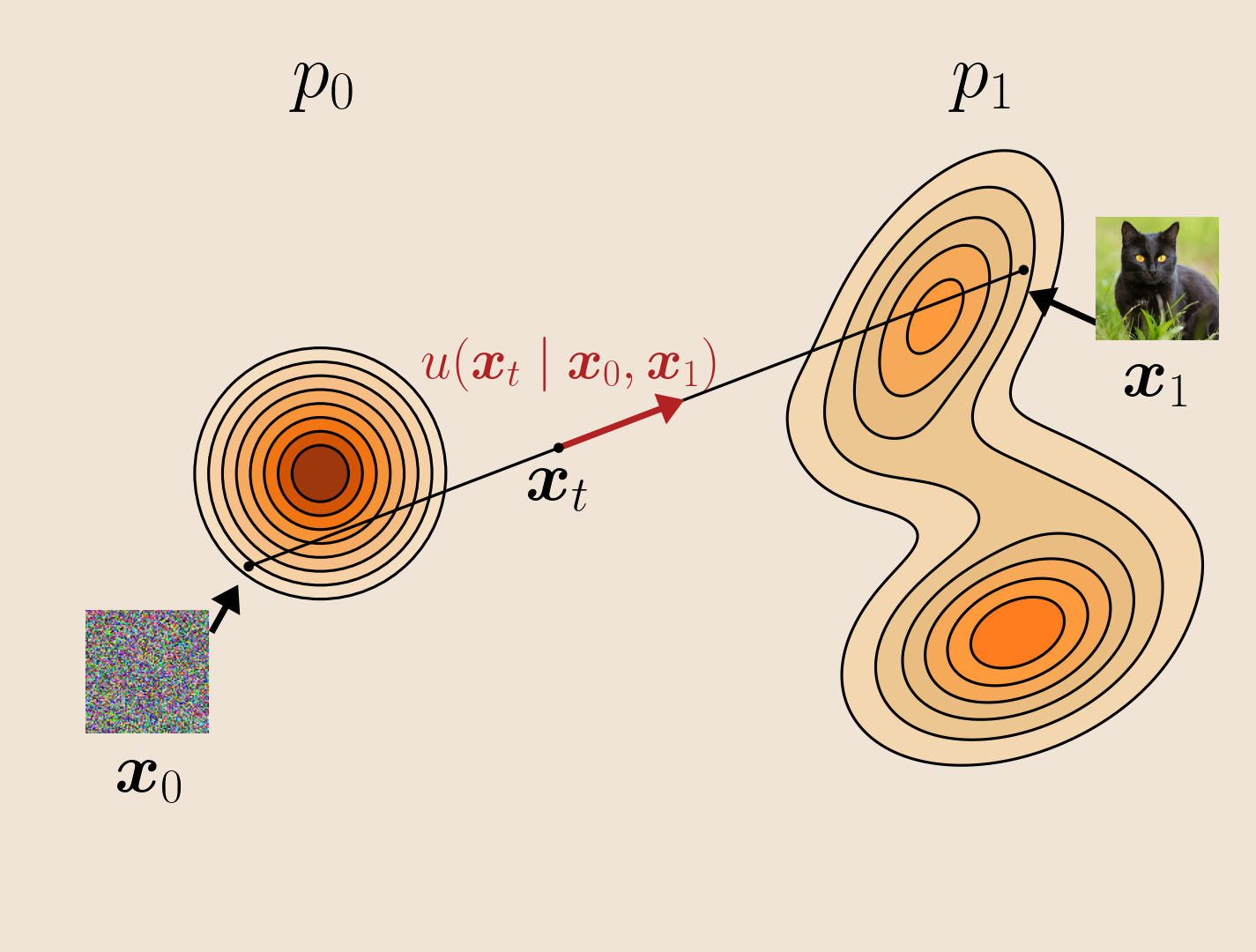
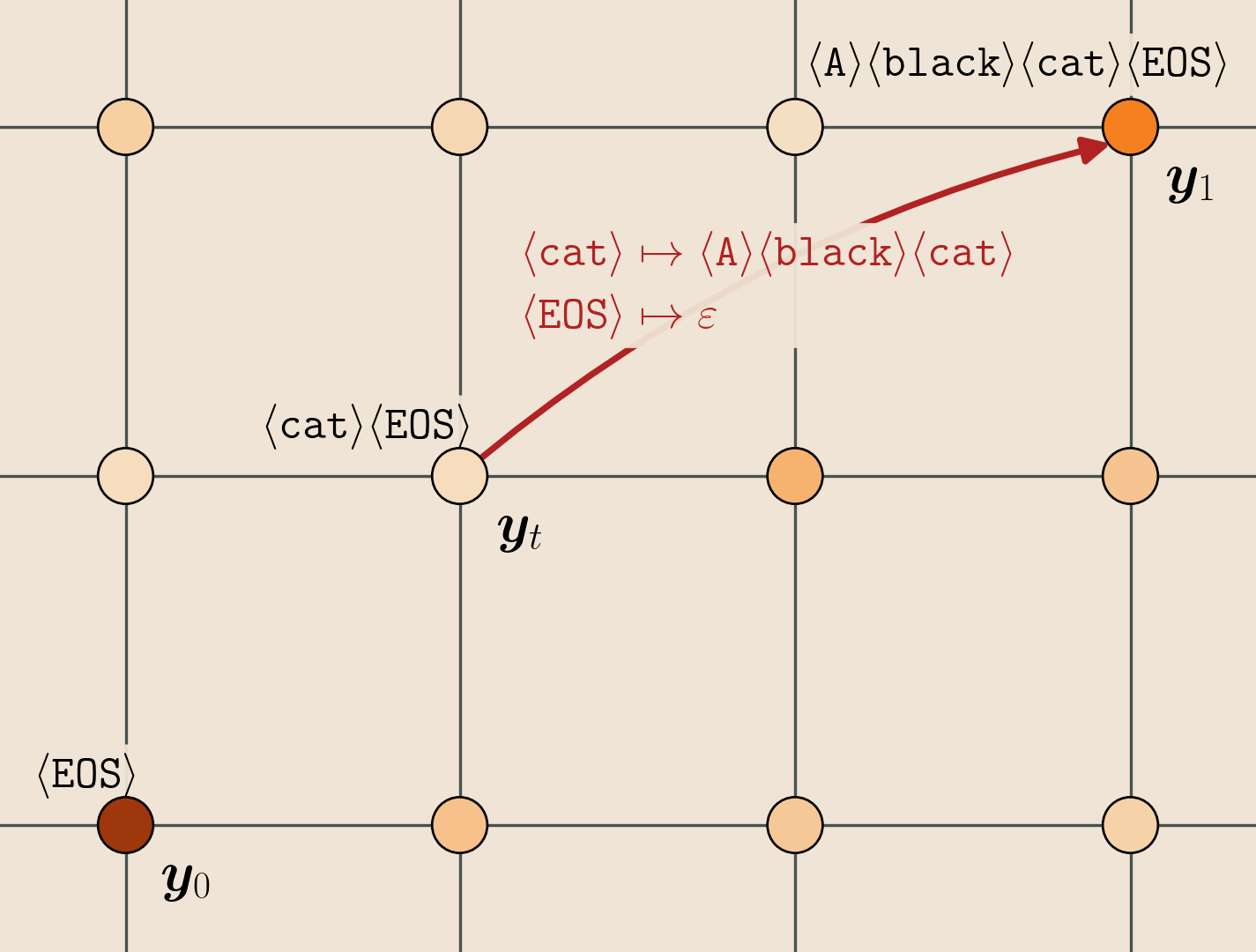
C2 — Native-space joint flow
Keep images in the native continuous flow, add a discrete insertion process for text,
and decouple image and text timesteps so conditional, joint, and partial-text generation become
different trajectories in a single (t,τ) space.
C3 — Results
On SD3 and FLUX.1-dev, outperform a matched Dual Diffusion-LoRA baseline on text→image retention and
image→text quality, support downstream VQA, all while training on two commodity GPUs.